")
")
")
")
")
")
")
")
")
")
A set of mean flattened images that are obtained by applying
the 3DMM-STN to multiple images of the same person from the
UMDFaces
Dataset.
(Please hover over the image to see the subject's name
and the number of images used for averaging)
3D Morphable Models as Spatial Transformer Networks
This page shows how to use a 3D morphable model as a spatial transformer within a convolutional neural network (CNN). It is an extension of the original spatial transformer network in that we are able to interpret and normalise 3D pose changes and self-occlusions. The network (specifically, the localiser part of the network) learns to fit a 3D morphable model to a single 2D image without needing labelled examples of fitted models.
The proposed architecture is based on a purely geometric approach in which only the shape component of a 3DMM is used to geometrically normalise an image. Our method can be trained in an unsupervised fashion, and thus does not depend on synthetic training data or the fitting results of an existing algorithm.
In contrast to all previous 3DMM fitting networks, the output of our 3DMM-STN is a 2D resampling of the original image which contains all of the high frequency, discriminating detail in a face rather than a model-based reconstruction which only captures the gross, low frequency aspects of appearance that can be explained by a 3DMM.
Usage & Training
We train our network using the MatConvNet library. Plese refer to the installation page for the instructions.
In order to start the training, you need to create the resampled expression model first. To do that, you need (1) Basel Face Model, 01_MorphableModel.mat and (2) 3DDFA Expression Model, Model_Expression.mat. You can set the paths accordingly and run the prepareExpressionBFM function in the prepareModel folder to build a resampled expression model.
Finally, run the dagnn_3dmmasstn.m script to start the training.
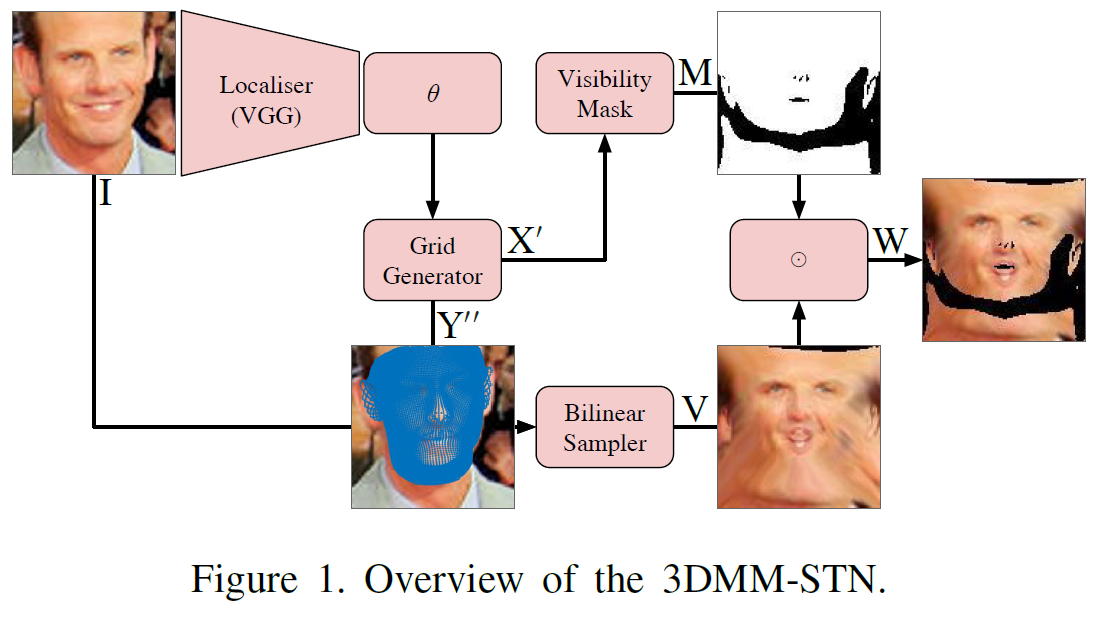
Localiser Network
The localiser network is a CNN that takes an image as input and regresses the pose and shape parameters, theta (θ = r, t, logs, α). For our localiser network, we use the pre-trained VGGFaces architecture, delete the classification layer and add a new fully connected layer with 6 + D outputs. The pre-trained models can be downloaded from MatConvNet model repository.
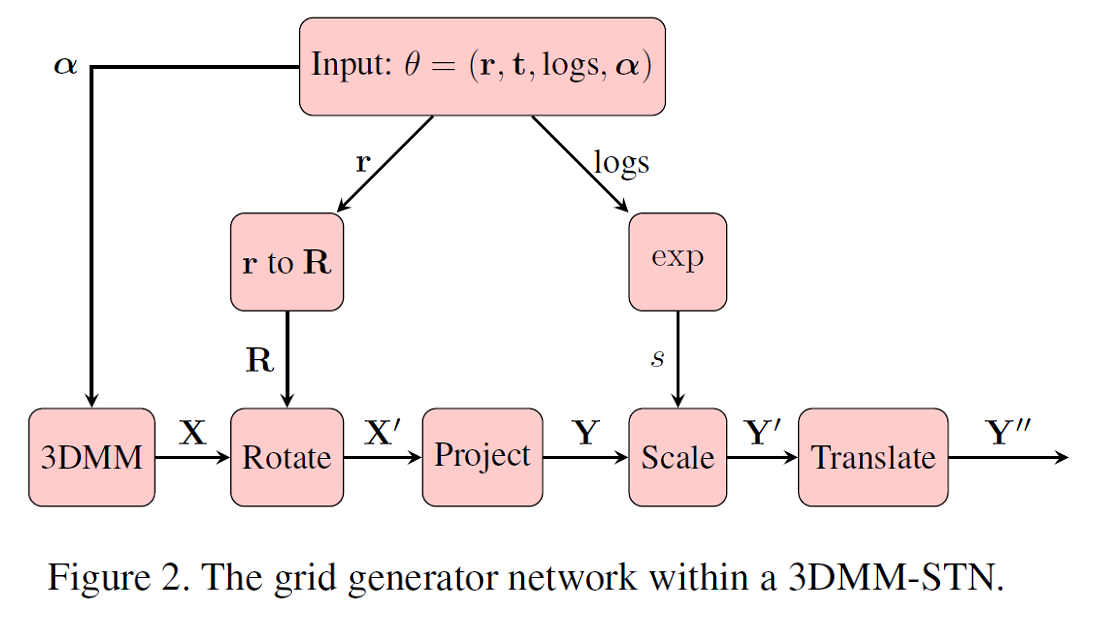
Grid Generator Network
Our grid generator combines a linear statistical model with a scaled orthographic projection. We apply a 3D transformation and projection to a 3D mesh that comes from the morphable model. The intensities sampled from the source image are then assigned to the corresponding points in a flattened 2D grid.
UV texture space embedding for Basel Face Model
The output of our 3DMM-STN is a resampled image in a flattened 2D texture space in which the images are in dense, pixel-wise correspondence. In other words, the output grid is a texture space flattening of the 3DMM mesh. Specifically, we compute a Tutte embedding using conformal Laplacian weights and with the mesh boundary mapped to a square. To ensure a symmetric embedding we map the symmetry line to the symmetry line of the square, flatten only one side of the mesh and obtain the flattening of the other half by reflection.
You can find the UV coordinates as BFM_UV.mat file on GitHub.


Customised Layers
In this section, we summarise our customised layers and loss functions. Please refer to the paper for more details.
- 3D morphable model layer generates a shape X, comprising N 3D vertices by taking a linear combination of principal components stored in the matrix and the mean shape, according to shape parameters α.
- Axis-angle to rotation matrix layer converts an axis-angle representation of a rotation, r, into a rotation matrix R.
- 3D rotation layer takes as input a rotation matrix R and N 3D points X, and applies the rotation.
- Orthographic projection layer takes as input a set of N 3D points X' and outputs N 2D points Y by applying an orthographic projection along the z axis.
- Scaling layers scale the 2D points Y based on scale s, after the log scale logs transformed to scale s.
- Translation layer generates the 2D sample points by adding a 2D translation t to each of the scaled points.
- Grid layer takes as input 2xN points and produces 2xH'W' grid using re-sampled 3DMM which has N=H'W' vertices and each vertex i, has an associated UV coordinate. To understand how to compute the re-sampled model over a uniform grid in the UV space, please refer to the resampleModel function and the sampling section of the paper.
- Bilinear sampler is a layer that is exactly as in the original STN.
- Visibility (self-occlusions) layer takes as input the rotation matrix R and the shape parameters α and outputs a binary occlusion mask M.
- Masking layer combines the sampled image and the visibility map via pixel-wise products.
Geometric Loss Functions
- Bilateral symmetry loss measures asymmetry of the sampled face texture over visible pixels.
- Siamese multi-view fitting loss penalises differences between multiple images of the same face in different poses.
- Landmark loss minimises the Euclidean distance between observed and predicted 2D points.
- Statistical prior loss minimises an appearance error, regularising the statistical shape prior (We scale the shape basis vectors such that the shape parameters follow a standard multivariate normal distribution).
Dependencies
- map_tddfa_to_basel.mat file is supplied by James Booth.
- Basel Face Model is freely available upon signing a license agreement via the website of Graphics and Vision Research Group, University of Basel.
- The expression model is using the correspondence to the Basel Model provided by 3DDFA. The components originally come from FaceWarehouse.